This section explains how creating portals on Qumulo clusters, and establishing relationships between spoke portals and hub portals, enables Cloud Data Fabric functionality in Qumulo Core.
A spoke portal root directory can either map to a unique hub portal root directory or share hub portal root directories with other spoke portals. To enable Cloud Data Fabric functionality, you must define a spoke portal on one cluster, a hub portal on another cluster, and then propose a portal relationship between the two.
-
For a general conceptual introduction, see What is Hub and Spoke Topology?.
-
For specific implementations of the Cloud Data Fabric functionality in Qumulo Core, see Example Cloud Data Fabric Scenarios.
- Qumulo Core 7.6.2 (and higher) adds the ability to have multiple root directories for each relationship and changed some of the existing terminology concerning portal relationship states and portal root directory states. For more information, see How Multiple Root Directories Work in Qumulo Core 7.2.0 (and Higher).
- Before you begin to implement Cloud Data Fabric in your organization, we strongly recommend reviewing the key terms, functionality explanation, example scenarios, and the known limits.
- For any questions, contact the Qumulo Care Team.
Key Terms
The following key terms help define the components of Cloud Data Fabric functionality in Qumulo Core.
Clusters and Root Directories
- Cluster: Any Qumulo cluster that shares a portion of its file system for a hub portal or a spoke portal. A directory on a cluster defines a root directory for a spoke portal or a hub portal.
Because a portion of a Qumulo cluster's file system can hold the hub portal root directory or spoke portal root directory, using the correct terminology can help avoid confusion:
- ❌ hub cluster
- ✅ hub portal host cluster
- ❌ spoke cluster
- ✅ spoke portal host cluster
- Spoke Portal Root Directory, Hub Portal Root Directory: A directory on a cluster that uses a portion of its file system for the hub portal or spoke portal.
According to the file system permissions that a hub portal might impose, you can access a spoke portal root directory by using NFSv3, NFSv4.1 (Qumulo Core 7.4.3 and higher), SMB, the S3 API (7.5.3 and higher) or the Qumulo REST API.
In Qumulo Core 7.6.2 (and higher), it is possible to configure up to 32 spoke portal root directories for each Qumulo cluster, for each portal relationship.
- Hub Portal Data: Accessible to other Qumulo clusters through a portal relationship or through replication, and to clients that connect to the hub portal host cluster
- Spoke Portal Data: Accessible only to clients that connect to the spoke portal host cluster
- Cluster-Local Data: Data on a hub portal host cluster or spoke portal host cluster which is located outside of the corresponding portal root directory, accessible to clients that connect to the cluster or to other Qumulo clusters through replication
The following table illustrates the various content types and ways in which this data can be accessed.
| Data Type | Data Accessible Through… | |||
|---|---|---|---|---|
| Other Qumulo clusters through portal relationships | Other Qumulo clusters through replication | Clients that access the spoke portal host cluster | Clients that access the hub portal host cluster | |
| Hub Portal Data | ✅ | ✅ | ❌ | ✅ |
| Spoke Portal Data | ❌ | ❌ | ✅ | ❌ |
| Cluster-Local Data | ❌ | ✅ | ✅ | ✅ |
How Multiple Root Directories Work in Qumulo Core 7.2.0 (and Higher)
In Qumulo Core 7.2.0 (and higher), clusters can take advantage of the Cloud Data Fabric functionality that lets clusters across disparate geographic or infrastructural locations (on-premises and in the cloud) access the same data while maintaining independent namespace structures on each cluster (by setting a portion of the cluster’s file system as the portal root directory).
In Qumulo Core 7.6.2 (and higher), it is possible to configure up to 32 spoke portal root directories for each Qumulo cluster, for each portal relationship. A spoke portal root directory can either map to a unique hub portal root directory or share hub portal root directories with other spoke portals.
In addition, Qumulo Core 7.6.2 introduces the following changes:
-
We refer to portal states as portal relationship states and the
Authorizedportal state has become theAcceptedportal relationship state. -
We have added the
AuthorizedandUnauthorizedportal root directory states to indicate the stages of the root directory approval process. -
Although Qumulo Core still doesn’t support more than one relationship between two clusters, it is now possible to have a variety of configurations involving spoke portal root directories and hub portal root directories, for example:
-
One-to-One Mapping: A single spoke portal root directory maps to a unique hub portal root directory (with multiple one-to-one mappings in parallel, as necessary)
-
Many-to-One Mapping: Multiple spoke portal root directories map to a shared hub portal root directory
-
Combined One-to-One and Many-to-One Mapping: Multiple spoke portal root directories map to both unique and shared hub portal root directories
-
Portals
- Spoke Portal: An interface point on a Qumulo cluster that accesses a portion of the file system on another cluster (which has a hub portal). A directory on a cluster defines a root directory for spoke portal. The spoke portal initiates the creation of a hub portal. You can configure multiple spoke portals on the same Qumulo cluster, as long as the spoke portal root directories don’t overlap and the host cluster for each portal relationship is unique.
- Read-Write Portal: A spoke portal that can access, modify, and create any files or directories within one or more corresponding hub portal root directories (in the
Authorizedstate) according to file system permissions.
- Read-Only Portal: A spoke portal that can access any files or directories within one or more corresponding hub portal root directories (in the
Authorizedstate) according to file system permissions, but can’t modify or create any files or directories regardless of file system permissions.
- Hub Portal: An interface point on a Qumulo cluster that shares a portion of its file system with another cluster (which has a spoke portal). A directory on a cluster defines a root directory for hub portal. The spoke portal initiates the creation of a hub portal. You can configure multiple portal relationships, with the same hub portal root directory, with nested directories, or with independent ones.
- It isn't possible to create a hub portal without a spoke portal. For example, a spoke portal on Cluster A can propose a portal relationship to Cluster B. This action initiates the creation of a hub portal in a
Pendingstate on Cluster B. - You must accept the portal relationship and then authorize any hub portal root directories before you can use them.
- While a spoke portal can be either read-only or read-write, a hub portal is always read-write.
- Portal Relationship: A proposal that a spoke portal on one Qumulo cluster issues to another Qumulo cluster (with a hub portal), which the Qumulo cluster with the hub portal accepts.
- Peer Portal: A portal that serves as a counterpart to another portal. For example, a hub portal is a peer portal to a spoke portal.
- Peer Portal Address: The IP address for a peer portal.
Portal Relationship States
A portal relationship state indicates the stages of the spoke portal creation process, and the proposal or deletion of a portal relationship.
| State | Description |
|---|---|
|
Qumulo Core has established a relationship between the spoke portal and a hub portal, but the hub portal hasn't yet accepted the relationship. Run the |
|
Both Qumulo clusters have acknowledged the portal relationship. Data in authorized hub portal root directories is accessible, if full connectivity between Qumulo clusters is established. |
|
Qumulo Core is in process of synchronizing any outstanding changes from the spoke portal to the hub portal. When synchronization is complete, Qumulo Core removes the portal relationship from each cluster. |
Portal Root Directory States
A portal root directory state indicates the stages of the hub portal root directory approval process.
In Qumulo Core 7.6.2 (and higher), it is possible to configure up to 32 spoke portal root directories for each Qumulo cluster, for each portal relationship. Each unique hub portal root directory has its own state.
| State | Description |
|---|---|
|
The spoke portal has requested access to a hub portal root directory. The hub portal hasn't yet authorized access. Run the |
|
The hub portal has authorized access to the hub portal root directory. Data in the hub portal root directory is accessible, if full connectivity between Qumulo clusters is established. Run the |
Portal Statuses
A portal status indicates the accessibility of a spoke portal or hub portal.
| Status | Description |
|---|---|
|
The portal relationship is in process of being configured.
|
|
All required connections between the spoke portal and hub portal are established.
|
|
Some or all required connections between the spoke portal and hub portal are missing.
|
How Cloud Data Fabric Functionality Works
This section explains the creation of portal relationships, data caching and synchronization, permissions in portal root directories, and the deletion of portal relationships.
Portal Relationship Creation
When you accept the portal relationship, if you run the qq portal_accept_hub
command with the --authorize-hub-roots flag, the hub portal also authorizes access to a hub portal root directory whose contents become available to the spoke portal immediately.
Data Synchronization
The cache of a spoke portal is inherently ephemeral. You must not use it in place of data replication or backup.
For read-write portals, data synchronization is bidirectional, asynchronous, and strictly consistent upon access. For example, when a client creates or modifies files or directories in the spoke portal root directory, the spoke portal synchronizes these changes to the hub portal in the background. Clients that access the hub portal can see these changes immediately.
To ensure that any changes on one portal become available immediately to any client that reads data from the portal’s peers, Qumulo Core uses a proprietary locking synchronization mechanism.
In Qumulo Core 7.6.3.1 (and higher), if two Qumulo clusters use a load balancer or if the portal relationship is configured by using the IP addresses of peer portals, portal data synchronization can achieve higher IOPS and throughput by making full use of all nodes from both Qumulo clusters in a portal relationship.
Data Caching
The first time a client accesses a spoke portal root directory, the spoke portal begins to read and cache data from the hub portal. Subsequent access to the same data accesses the cache of the spoke portal host cluster, with performance characteristics equivalent to access to non-portal data on the spoke portal host cluster.
Caching takes place on demand, when a client with access to the spoke portal retrieves new portions of the namespace that the hub portal provides. For more information, see Configuring Cache Management for Spoke Portals in Qumulo Core.
Portal Root Directory Permissions
Qumulo Core enforces permissions in the same way for files and directories in the spoke portal root directory and the hub portal root directory.
- Deleting the portal relationship never affects the data on the hub portal.
- For a spoke portal to be accessible, there must be full connectivity between the two clusters in a portal relationship, without which files or directories with outstanding modifications on one portal are inaccessible on other portals. Specifically, every node in the spoke portal host cluster must be able to connect to the configured hub portal host cluster address, and the other way around.
Portal Relationship Deletion
This section explains the sequence of events when you request the removal of the portal relationship from the spoke portal or the hub portal.
-
When you request the removal of the spoke portal, the relationship becomes read-only and enters the
Deletingstate and Qumulo Core begins to synchronize any outstanding changes from the spoke portal to the hub portal. -
During deletion, the relationship requires connectivity to make progress, indicated by the Active status.
-
After deletion completes, Qumulo Core:
-
Removes the spoke portal and hub portal configuration entries automatically
-
Deletes the spoke portal root directory and reclaims the capacity previously consumed by cached data.
-
When you remove a portal relationship, any files or directories on the hub portal that were inaccessible, due to both connectivity loss and outstanding spoke portal modifications, become accessible.
Portal Operation Audit Logging
-
For clients accessing spoke portal data, audit logging is determined by the configuration on the spoke portal host cluster.
-
For clients accessing hub portal data, audit logging is determined by the configuration on the hub portal host cluster.
Example Cloud Data Fabric Scenarios
The following are examples of some of the most common scenarios for workloads that use Cloud Data Fabric functionality.
Edge Clusters
In this scenario, you deploy a single, large central cluster at your organization’s data center and multiple, small edge clusters at your organization’s branch offices or in remote locations.
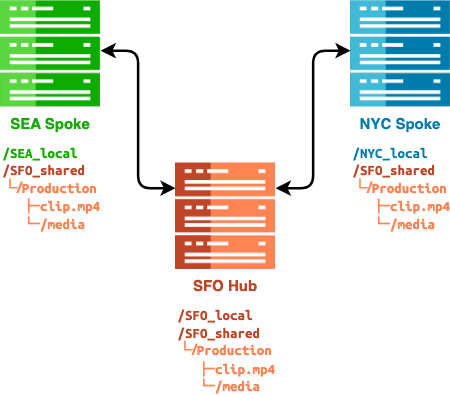
The Cloud Data Fabric functionality lets you make the data on the central cluster available to the remote clusters without the need to replicate data to each location. The data remains available to the edge clusters even if their capacity is lower than that of the central cluster. While a read-write portal lets the edge clusters create or modify data on the central cluster, a read-only portal lets only the edge clusters read data from the central cluster.
Active Workload with Archive
In this scenario, several clusters serve active workloads but require access to a large data archive after the initial workflow completes.
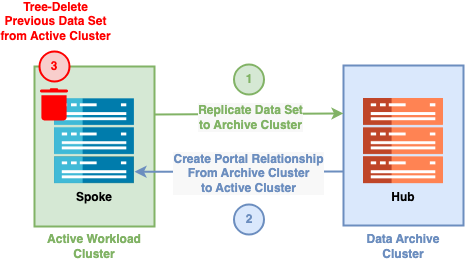
The Cloud Data Fabric functionality lets you:
-
Move your cold (infrequently accessed) data to a central archive cluster and then provide access to this data by using a portal on the original cluster.
The active workload clusters can reclaim most of the data set capacity that was tiered to the data archive cluster. This makes it possible to access all of the data as before, while using only the capacity on the active workload clusters for the data that your system reads through the portal.
-
Serve specific archive capacity and performance needs by scaling the archive cluster independently of any active workflow clusters.